Todas las semanas escogemos un proyecto de la vida real para que construyas tu portafolio y te prepares para conseguir un trabajo. Todos nuestros proyectos están construidos con ChatGPT como co-pilot!
Únete al retoUn podcast de cultura tecnológica donde aprenderás a luchar contra los enemigos que te bloquean en tu camino para convertirte en un profesional exitoso en tecnología.
Escuchar el podcastComputación en la Nube
La computación en la nube (cloud computing) es un modelo de entrega de servicios de tecnología a través de Internet. En lugar de tener que comprar y mantener servidores y hardware propios, las empresas y/o los usuarios pueden acceder a recursos informáticos, como servidores, almacenamiento, bases de datos, redes y software, a través de proveedores de servicios en la nube.
En esencia, el cloud computing permite a las organizaciones y a los individuos utilizar recursos informáticos de manera flexible y bajo demanda, pagando solo por lo que realmente utilizan. Esto proporciona varias ventajas, como:
- Escalabilidad: Los recursos pueden escalarse hacia arriba o hacia abajo según las necesidades, lo que permite un uso eficiente de los recursos y la capacidad de manejar cargas de trabajo variables.
- Acceso remoto: Los usuarios pueden acceder a sus aplicaciones y datos desde cualquier lugar con conexión a Internet, lo que facilita la colaboración y el trabajo remoto.
- Coste reducido: Al no requerir inversión en infraestructura física ni hardware, las organizaciones pueden evitar costes iniciales y gastos de mantenimiento. Solo pagan por los recursos que consumen.
- Actualizaciones y mantenimiento simplificados: Los proveedores de servicios en la nube se encargan de la administración de hardware y software, lo que libera a los usuarios de la carga de mantenimiento.
- Flexibilidad: Ofrecen una variedad de opciones y configuraciones para satisfacer las necesidades específicas de diferentes usuarios y empresas.
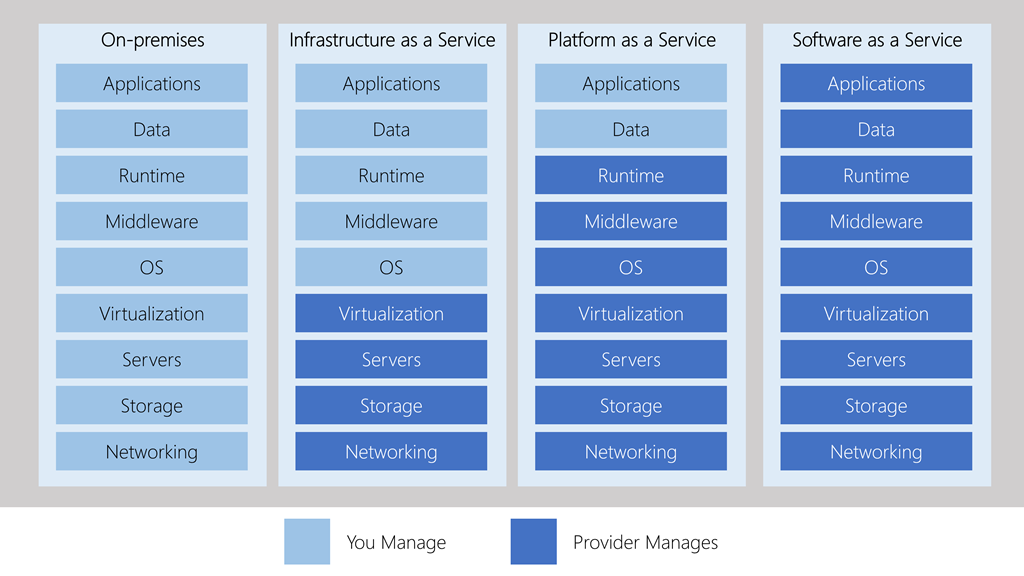
Hay tres modelos principales de servicios en la nube:
- Infraestructura como servicio (IaaS, Infraestructure as a Service): Proporciona acceso a recursos de infraestructura básicos, como servidores virtuales, almacenamiento y redes. En este tipo de servicio, básicamente obtenemos una parte de una(s) computadora(s) gigante(s) en la nube. Es como alquilar solo el hardware de una computadora. Aquí, nosotros somos responsables de administrar todo, como instalar sistemas operativos y programas. Puede ser muy flexible, como si estuviéramos construyendo nuestra propia casa y eligiendo cada detalle. Ejemplos son servicios como Amazon Web Services (AWS) y Microsoft Azure.
- Plataforma como servicio (PaaS, Platform as a Service): Ofrece un entorno de desarrollo y ejecución para que los desarrolladores construyan, implementen y gestionen aplicaciones sin preocuparse por la infraestructura subyacente. Este servicio es como si nos diesen un lugar en la nube para construir nuestra casa, pero ya tenemos algunas herramientas y materiales específicos listos para usar. Podemos construir aplicaciones usando esas herramientas sin preocuparnos por la infraestructura básica. Es como si alguien nos diera un kit de construcción para hacer nuestra casa en lugar de tener que diseñar cada pieza nosotros mismo. Ejemplos incluyen Google App Engine y Heroku.
- Software como servicio (SaaS, Software as a Service): Ofrece aplicaciones completas a través de la nube. Los usuarios pueden acceder y utilizar el software a través de un navegador web sin necesidad de instalar o mantenerlo localmente. Con SaaS, en realidad no tenemos que construir nada. Es como si ya tuviéramos una casa completamente amueblada y lista para vivir. Solo necesitamos entrar y empezar a vivir. En lugar de instalar programas en nuestro ordenador, accedemos a ellos a través de Internet. Por ejemplo, como sucede en Gmail o Google Docs. No necesitamos preocuparnos por las cosas técnicas, solo usar lo que está ahí.
| IaaS (Infraestructura como Servicio) | PaaS (Plataforma como Servicio) | SaaS (Software como Servicio) | |
|---|---|---|---|
| Nivel de Abstracción | Baja | Mediana | Alta |
| Responsabilidad de Gestión | Usuario (Sistemas Operativos, Redes) | Proveedor (Plataforma, Middleware) | Proveedor (Aplicación) |
| Flexibilidad | Alta | Moderada | Baja |
| Escalabilidad | Alta | Moderada | Limitada |
| Desarrollo de aplicaciones | Depende del usuario | Basado en Plataforma | No necesario, solo uso |
| Ejemplos | Máquinas virtuales (AWS, Azure) | Google App Engine, Heroku | Salesforce, Google Workspace |
La computación en la nube, en términos del Machine Learning y, más allá, de la Inteligencia Artificial, hoy en día se utiliza en todas sus formas; desde utilizar herramientas de terceros para desarrollar modelos como entornos de desarrollo completamente integrados en la nube, pasando por desarrollos locales y el despliegue en la nube (éste último el más utilizado).
Machine learning en la nube
A pesar de que hay un catálogo infinito y muy bien repartido de servicios para trabajar en el ámbito del machine learning, algunos de los más destacados y conocidos son:
- Amazon Web Services (AWS): AWS ofrece una amplia gama de servicios para machine learning, como Amazon SageMaker, que es una plataforma integral para construir, entrenar e implementar modelos de machine learning. También proporciona servicios específicos como Amazon Rekognition para reconocimiento de imágenes y Amazon Polly para síntesis de voz.
- Microsoft Azure: Azure Machine Learning es la oferta de machine learning en la nube de Microsoft. Proporciona herramientas y servicios para desarrollar, entrenar y desplegar modelos de machine learning. También incluye Azure Cognitive Services para capacidades de procesamiento de lenguaje natural y visión computarizada.
- Google Cloud Platform (GCP): Google Cloud ofrece Google Cloud AI Platform, que permite construir, entrenar y desplegar modelos de machine learning utilizando TensorFlow y otros frameworks populares. También ofrece servicios de procesamiento de lenguaje natural a través de la API Cloud Natural Language y el reconocimiento de imágenes a través de la API Cloud Vision.
- IBM Cloud: IBM ofrece IBM Watson, una plataforma de inteligencia artificial que abarca machine learning y análisis de datos. Watson Studio es una herramienta para crear y entrenar modelos, y Watson Machine Learning permite implementarlos. También ofrecen servicios de procesamiento de lenguaje natural y análisis de texto.
- Alibaba Cloud: El proveedor chino Alibaba Cloud ofrece servicios de machine learning a través de Alibaba Cloud Machine Learning Platform, que incluye herramientas para construir, entrenar y desplegar modelos. También ofrece servicios de procesamiento de lenguaje natural y visión computarizada.
- Oracle Cloud: Oracle Cloud proporciona servicios de machine learning y analítica avanzada a través de Oracle Cloud Infrastructure Data Science. Ofrece capacidades de modelado, entrenamiento y despliegue, así como integración con otras herramientas de Oracle.
Almacenes de datos en la nube
Los almacenes de datos en la nube son sistemas diseñados para almacenar grandes cantidades de información de manera eficiente y escalable. Con el aumento reciente en el tamaño de los conjuntos de datos y la potencia informática necesaria para ejecutar modelos de aprendizaje automático, aprovechar los recursos de la nube es una necesidad para la ciencia de datos.
En la gestión de los datos, dependiendo de cómo se almacenen, custodien y cuál es el uso que se les va a dar, existen distintas tecnologías disponibles.
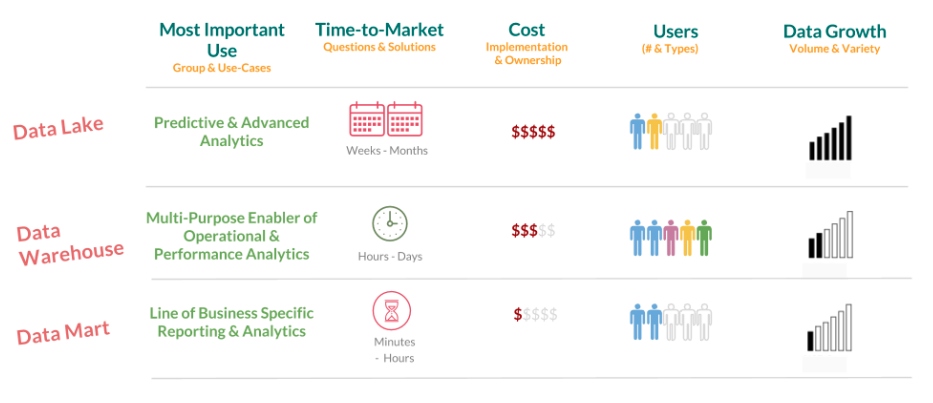
Data lake
Un largo de datos (Data Lake) es un depósito que almacena grandes volúmenes de datos en su formato original y sin procesar. Esto incluye datos estructurados, semiestructurados y no estructurados. La información se almacena en su forma cruda, lo que brinda flexibilidad para analizarlos en diferentes contextos y extraer información valiosa.
Esta tecnología es especialmente útil para el análisis de Big Data y la exploración de datos. Ejemplos de tecnologías utilizadas en Data Lakes son Hadoop y sistemas de almacenamiento en la nube como Amazon S3.
Data warehouse
Un almacén de datos (Data Warehouse) es un sistema centralizado que recopila, organiza y almacena datos de diferentes fuentes de una empresa en un formato estructurado y optimizado para consultas analíticas. Los datos en un Data Warehouse suelen ser históricos y están diseñados para respaldar la toma de decisiones basadas en informes y análisis. Los Data Warehouses a menudo utilizan modelos dimensionales y tablas de hechos para permitir consultas complejas. Ejemplos de Data Warehouses incluyen Amazon Redshift, Google BigQuery y Microsoft Azure Synapse Analytics.
Data mart
Un data mart (el término en castellano no se utiliza) es una versión más pequeña de un Data Warehouse. Está diseñado para atender las necesidades específicas de un departamento o grupo de usuarios dentro de una organización. Los Data Marts contienen una porción de los datos del Data Warehouse y están optimizados para un área de negocio particular. Son útiles para permitir a los usuarios acceder y analizar datos relevantes de manera más eficiente y específica. Los Data Marts pueden ser independientes o extraídos del Data Warehouse principal.
La principal diferencia entre un data lake y un data warehouse tiene que ver con el formato en el que se procesan y almacenan los datos. En un almacén de datos siempre encontraremos datos estructurados y preprocesados, y en un lago, no. Tomar la decisión sobre qué tecnología implantar dependerá del tipo de datos en el que trabajemos y la frecuencia con la que se actualizarán. Un data warehouse es un entorno más analítico, y no está destinado a consultas ni actualizaciones frecuentes.